Nowy model OpenAI o1, czyli długo wyczekiwana truskawka.

- Jak działa?
- Różnica między o1 a GPT-4o
- Jak ją najlepiej wykorzystać?
- Jak promptować?
- Bezpieczeństwo
- Czy zastąpi GPT-4o?
- Czy mam do niej dostęp?
- Ceny API
Jak działa?
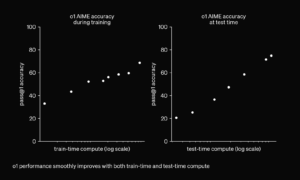
OpenAI deklaruje, że wypuścili nową serię modeli rozumowania do rozwiązywania trudnych problemów. Modele te zostały wytrenowane tak, aby poświęcały więcej czasu na analizę problemu przed udzieleniem odpowiedzi – tak, jak zrobiłby to człowiek. W trakcie treningu uczą się, jak ulepszać swoje procesy myślowe, wypróbowywać różne strategie i rozpoznawać popełniane błędy. OpenAI o1 osiąga wyniki w 89. percentylu w pytaniach z konkurencyjnego programowania (Codeforces), plasuje się wśród 500 najlepszych uczniów w USA w eliminacjach do Olimpiady Matematycznej (AIME), a także przewyższa dokładność na poziomie doktoranckim w dziedzinach takich jak fizyka, biologia i chemia (GPQA).
Dowiedziono również, że wydajność modelu o1 stale się poprawia wraz z większą ilością uczenia przez wzmacnianie (compute na etapie treningu) oraz z dłuższym czasem poświęcanym na myślenie (compute w trakcie odpowiadania na pytanie). Dlatego modelu o1 ani jego młodszego brata o1-mini nie ma w darmowej wersji planu ChatGPT.
https://openai.com/index/learning-to-reason-with-llms/
Jest to przełom – udało się skalować modele na nowy poziom. W obecnych systemach machine learning wydajność modelu jest ściśle powiązana z ilością mocy obliczeniowej poświęconej na proces treningowy. Co ciekawe, istnieje możliwość zwiększenia możliwości wytrenowanego modelu kosztem większej ilości obliczeń w trakcie wnioskowania (wyżej wspomniany chain of thought) lub zmniejszenia tej ilości obliczeń kosztem niższej wydajności. Na przykład modele mogą być „przycinane”, aby zmniejszyć koszt wnioskowania, lub mogą zostać instruowane do rozumowania w ciągach myślowych (chains of thought), co zwiększa koszt wnioskowania. To drugie podejście można zobaczyć w Claude 3.5 Sonnet w aplikacji webowej. Z odpowiedzi Claude można wyciągnać tag , który ma symulować wnioskowanie. Ale 1o to inna bajka, bo model był uczony na danych, które takie wnioskowanie posiadają, Claude swój tok myślowy ma zakodowany w prompcie systemowym na aplikacji webowej, czyli nie jest do końca przystosowany do takich odpowiedzi, dlatego otrzymuje rozkaz wbudowany w interfejs czatu. Korzystając z Claude 3.5 Sonnet przez API, bez żadnego promptu systemowego, nie osiągniemy tak dobrej odpowiedzi jak w ich interfejsie.
Więcej o tym jak można używać compute w modelach językowych piszą eksperci @pvllss i @diatkinson z @EpochAIResearch, oni już w lipcu 2023 roku napisali artykuł “Trading Off Compute in Training and Inference”, który doskonale wyjaśnia podejście, które OpenAI mogło wybrać.
Link: https://epochai.org/blog/trading-off-compute-in-training-and-inference
Świetną nitkę na X napisał też @DrJimFan z Nvidii.
Różnica między o1 a GPT-4o
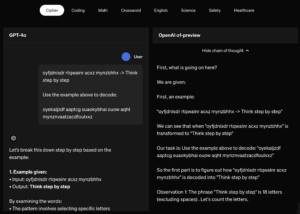
Doskonale ją widać przy skorzystaniu z tego modelu. Zanim odpowie, potrzebuje od 5 do 90 sekund na odpowiedź w zależności od trudności zadania. Przed wysłaniem odpowiedzi, model spędza dużo czasu na wnioskowaniu (chain of thought). W czacie na stronie OpenAI można podejrzeć skróconą wersję wnioskowania, jednak to co się dzieje z modelem doskonale oddaje porównanie GPT-4o i o1 na stronie OpenAI – https://openai.com/index/learning-to-reason-with-llms/
https://openai.com/index/learning-to-reason-with-llms/
Dlaczego w czacie wersja wnioskowania jest skrócona? To dlatego żeby nie trzeba było długo przewijać strony – user experience, nie marnować tokenów przez API lub (bardziej prawdopodobne) by konkurencja nie mogła uczyć swoich modeli na wnioskowaniu. To właśnie wnioskowanie jest tutaj kluczem. Konkurencja mając dostęp do tych danych, mogłaby szybko nadrobić zaległości ucząc nowy model na wnioskowaniach o1.
https://openai.com/index/learning-to-reason-with-llms/
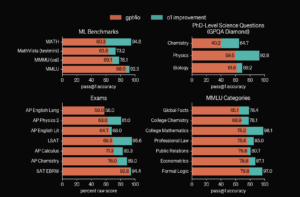
W 2024 roku GPT-4o rozwiązał średnio 12% (1.8/15) zadań na egzaminie AIME, zaprojektowanym dla najlepszych uczniów szkół średnich w Ameryce. o1 uzyskał średnio 74% (11.1/15) przy jednym podejściu do zadania, 83% (12.5/15) z konsensusem wśród 64 prób, oraz 93% (13.9/15) przy ponownym ocenianiu 1000 próbek za pomocą wyuczonej funkcji oceniającej. Wynik 13.9 plasuje go wśród najlepszych 500 uczniów w kraju i powyżej progu kwalifikacji do Olimpiady Matematycznej USA.
Model o1, po dalszym treningu skupionym na umiejętnościach programistycznych, uzyskał 213 punktów, plasując się w 49. percentylu w 2024 roku na Międzynarodowej Olimpiadzie Informatycznej (IOI). Model rywalizował na tych samych zasadach co ludzie, mając 10 godzin na rozwiązanie sześciu trudnych problemów algorytmicznych i 50 prób na każde zadanie. Oceny były dokonywane na podstawie wyników na publicznych testach IOI.
Do czego model jest dobry?
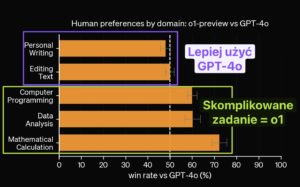
Jeśli planujesz używać tego modelu do pisania postów na blogu lub edycji tekstu, to źle planujesz. Użytkownicy, którzy mieli dostęp do modelu przed premierą, ocenili, że GPT-4o nadaje się do tego lepiej. To nie zmienia faktu, że o1 jest w tym dobry. Po co marnować limit wiadomości z takimi zadaniami, jak jest model, którego możesz używać bez limitu? Oczywiście, GPT-4o ma limit, tylko, że dużo większy. Na upartego można ten limit w planie Plus osiągnąć. Dzięki @barteksto za podesłanie.
https://openai.com/index/learning-to-reason-with-llms/
OpenAI podaje wskazówki: “te ulepszone zdolności rozumowania mogą być szczególnie przydatne, jeśli masz do czynienia ze skomplikowanymi problemami w dziedzinach takich jak nauka, programowanie, matematyka i pokrewne”. Ja tutaj widzę dodatkowo zastosowania takie jak:
- organizacja wydarzeń,
- tworzenie biznes planu,
- tworzenie planu na edukację domową,
- tworzenie planu na kampanię marketingową,
- tworzenie biznesu planu,
- raportowanie,
- tworzenie planu na aplikację.
To są nisko leżące owoce. Zadań, które wymagają takiego poziomu rozumowania jest o wiele więcej.

Zagadka logiczna z o1-preview
Na wczorajszym live na serwerze Discord Horyzont AI chwilę testowaliśmy ten model używając zagadek logicznych. Poniżej przykład @ChomatekLukasz i jego zagadki. Na początku model dawał złą odpowiedź, ale wyłapałem problem – za każdym razem o1 za każdym razem zakładał, że rura, w której znajdowała się piłka, jest od spodu zakrywana ręką podczas przenoszenia jej ze stołu w inne miejsce. Przy dodaniu informacji, że tak nie jest, model poprawnie rozwiązał zadanie.
Według OpenAI, ten model świetnie sobie radzi z zadaniami na poziomie doktoranckim. Na swojej stronie – https://openai.com/index/introducing-openai-o1-preview/ pokazują kilka przykładów z ekonomii, kodowania, kognitywistyki, genetyki i matematyki, gdzie o1 podawał odpowiedzi, które zostały zweryfikowane jako bardzo dobre przez ekspertów w danych dziedzinach.
Tutaj przykład tego jak o1 pomaga fizykowi kwantowemu – Mario Krennowi.
Jak pisać prompty?

https://platform.openai.com/docs/guides/reasoning
Te modele działają najlepiej w odpowiedzi na proste zapytania. Niektóre techniki tworzenia zapytań, takie jak podawanie kilku przykładów (few-shot prompting) lub polecenie modelowi „myślenia krok po kroku”, mogą nie poprawiać wyników, a czasami mogą nawet im przeszkadzać. Oto kilka najlepszych praktyk:
- Zachowaj prostotę i zwięzłość zapytań: Modele są doskonałe w rozumieniu i odpowiadaniu na krótkie, jasne instrukcje, bez potrzeby dodatkowych wyjaśnień.
- Unikaj zapytań z myśleniem krok po kroku: Ponieważ te modele wykonują rozumowanie wewnętrznie, proszenie ich o “myślenie krok po kroku” lub “wyjaśnianie rozumowania” nie jest konieczne.
- Używaj separatorów dla przejrzystości: Używaj separatorów, takich jak potrójne cudzysłowy, znaczniki XML lub tytuły sekcji, aby wyraźnie wskazać różne części wejściowe, co pomaga modelowi odpowiednio je zinterpretować.
- Ogranicz dodatkowy kontekst w generowaniu z rozszerzonym dostępem do danych (RAG): Podając dodatkowy kontekst lub dokumenty, uwzględnij tylko najbardziej istotne informacje, aby zapobiec nadmiernemu komplikowaniu odpowiedzi modelu.
o1-preview i o1-mini – co to za modele?

https://openai.com/index/learning-to-reason-with-llms/
OpenAI o1-preview to wczesna wersja modelu o1, natomiast OpenAI o1-mini to szybsza wersja, która jest szczególnie skuteczna w programowaniu.
Bezpieczeństwo

https://openai.com/index/learning-to-reason-with-llms/
Model o1-preview osiągnął znacznie lepsze wyniki w kluczowych testach dotyczących przełamywania zabezpieczeń oraz w najtrudniejszych wewnętrznych benchmarkach OpenAI oceniających granice bezpieczeństwa i odmowy modelu. Ja i tak czekam na @elder_plinius, na pewno coś wymyśli.

https://cdn.openai.com/o1-system-card.pdf
Dodatkowo (znalezione w karcie modelu o1 przez @kaqukal) odpowiedzi i proces myślowy modelu jest monitorowany przez GPT-4o.
Czy o1 zastąpi GPT-4o?
Nie, OpenAI o1 to kolejna rodzina modeli. GPT-Next, GPT-5, itd. dalej są w planach.
Dostęp i limity
Aplikacja ChatGPT
Wszyscy użytkownicy ChatGPT planów Plus i Teams mają już dostęp. Jeśli nie opłacasz subskrypcji ChatGPT, to nie masz dostępu do nowych modeli. Użytkownicy planów Enterprise i Edu otrzymają dostęp w następnym tygodniu. API: Masz do niego dostęp, jeśli jesteś w 5 tierze użytkowników, czyli takich, którzy doładowali konto za minimum $1 000.
Szanuj swoje tokeny! W ciągu tygodnia możesz wysłać tylko 30 wiadomości do o1-preview i 50 wiadomości do o1-mini. Po wykorzystaniu limitu musisz odczekać tydzień.
API
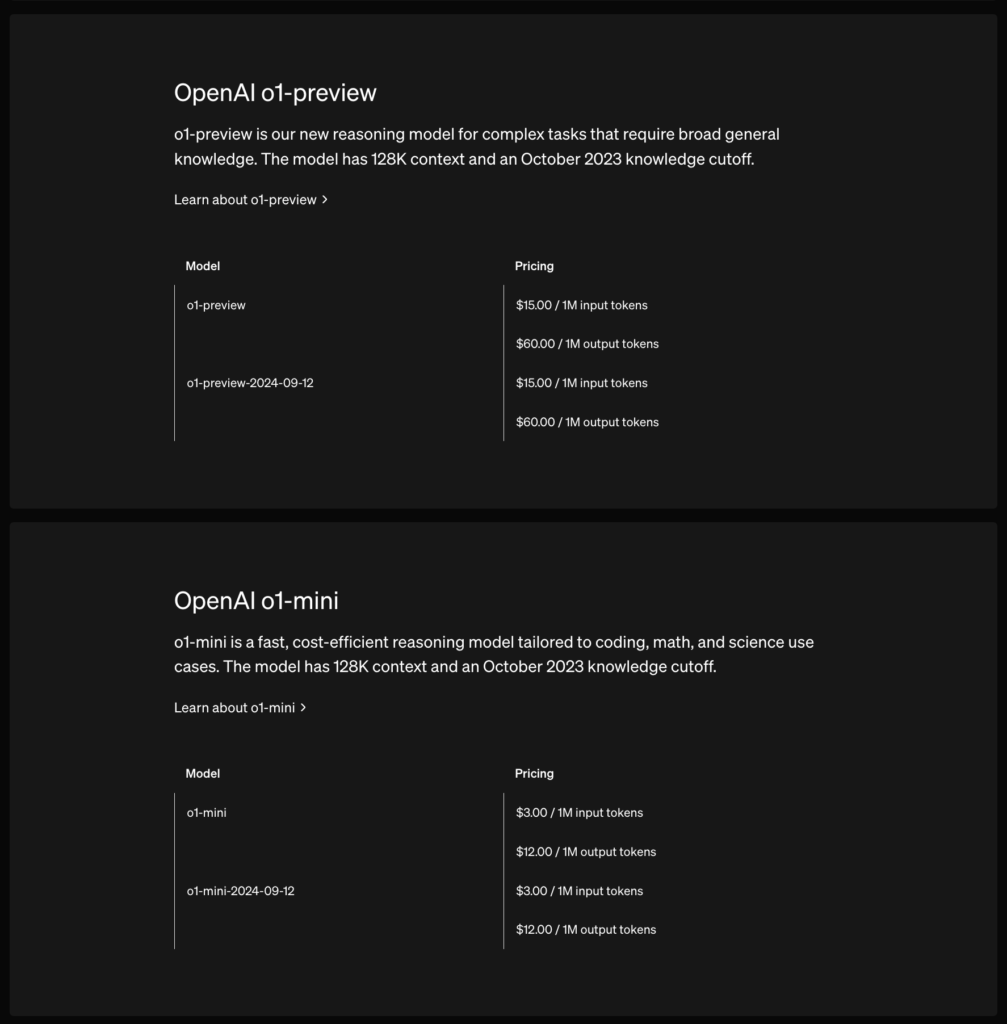
Modele o1-preview i o1-mini oferują okno kontekstowe o wielkości 128 000 tokenów. Każda odpowiedź ma górny limit na maksymalną liczbę tokenów wyjściowych – obejmuje to zarówno niewidoczne tokeny związane z procesem rozumowania, jak i widoczne tokeny odpowiedzi. Więcej o tym tutaj: https://platform.openai.com/docs/guides/reasoning
Maksymalne limity tokenów wyjściowych wynoszą:
- o1-preview: do 32 768 tokenów
- o1-mini: do 65 536 tokenów
Obecny limit zapytań to 20 na minutę (liczba ma wzrosnąć wkrótce).
API nie wspiera wzywania funkcji, generowania obrazów ani przeszukiwania internetu.
https://openai.com/api/pricing/
Aktualizacja 13/05/2024, 05:00: Model został zjailbreakowany.